

Ever heard of a graph database? Maybe not but you’ve certainly seen them in action.

Last year we began working with Amazon’s Neptune graph database solution. This AWS-friendly solution places graph database technology into a very familiar eco-system for many enterprises and has allowed us to greatly enhance the performance of real-time highly related customer data from the web, apps, and smart devices.
Have you done any online shopping recently? Did you see anything like: “You might also enjoy” or “customers who bought this also bought”? Maybe you’ve looked through your friend recommendations on a certain social site or listened to a “radio” station on a streaming service based on your favorite song. How does all this magic happen on sites like Facebook, Netflix, and Amazon?
The key to all of this magic is relationships, specifically relationships between pieces of data. It’s relationships like this that are the focus of Graph Databases. They are especially good at understanding, connecting, and performing operations on relationships far more so than traditional relational databases (i.e. Oracle, SQL Server) and document stores (Mongo, Couch).
What exactly are we talking about when we talk about Graph databases though? Well to explain that I want you to dive back into your memory. Go back to high school geometry or middle school algebra. You probably did some plotting of equations, vertices, edges or drew circles with bisecting lines. Can you recall the graph paper, or graphing calculator with x and y-axis, dots and lines connecting them? Is it all flooding back to you yet? It’s related – I can prove it to you. (get it – prove, geometry? sigh)
Graphs are collections of vertices (points) and possibly edges (lines) connecting them. You can have a graph without edges, containing only vertices but if you have edges though they must connect two vertices. Those are the basic rules of graphs, there are lots of shapes that can be formed, there can be directed edges that are going from one vertex to another vertex or that edge can be undirected, they simply share an edge. OK, so we’ve got some rules about graphs how does that possibly apply to data though?
Let’s look at an example.
Here’s you as a graph.

You have friends, right? Sure you do. You are one cool cat. I am not going to show them all though. Let’s add a few of them to the graph.

We’ve already hinted at it, but you have a relationship with each of those dots, they are your friends. Let’s connect you to your friends with a line.
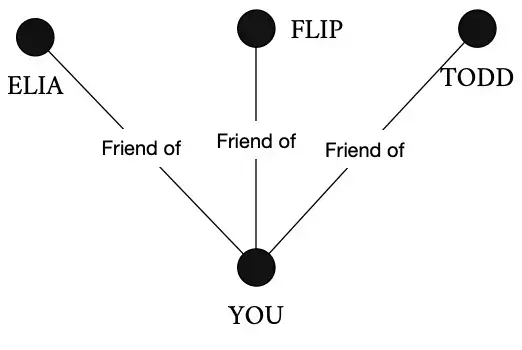
This is you and your friends as a graph.
You all work at the same place – let’s add that to the graph.
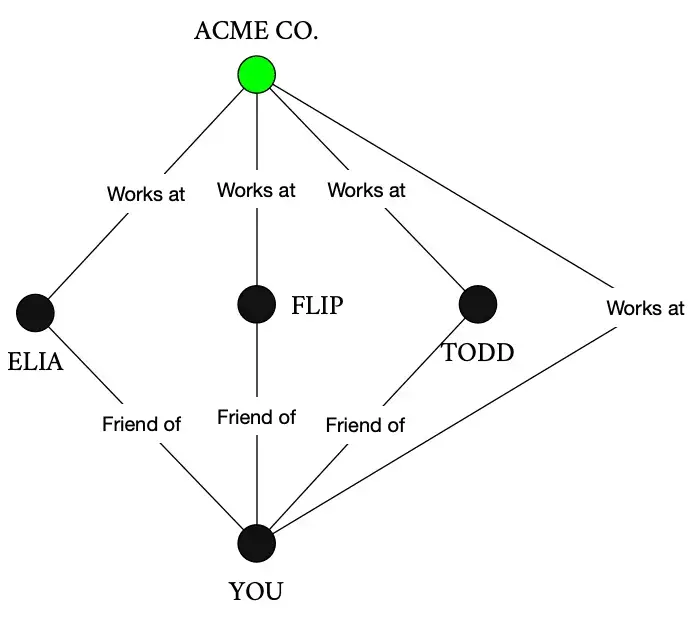
Some of your friends are managers and one of them manages you directly. Let’s add that to the graph too.
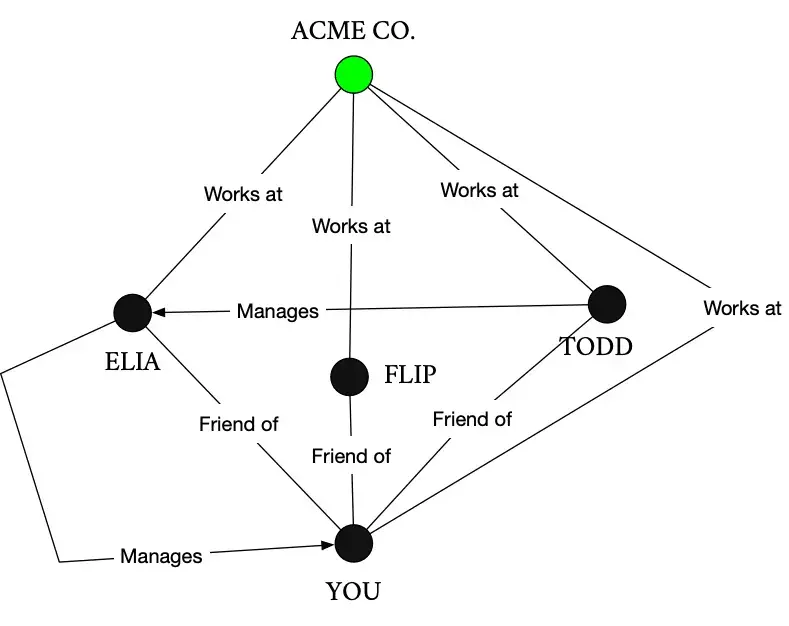
All of this information is the graph. Imagine if we were to add all of your friends’ friends or the rest of the employees of the company. We’d start to have a real web of vertices and edges. Vertices might connect in peculiar ways and we could learn a lot about this data set of you and your friends and their friends and the company you work at just by looking at the data. That’s an inkling of the power of graphs in databases. Being able to look at all of those relationships and see how they are connected.
For graph databases the main component is the graph itself, its vertices (entities) and edges (relationships). That is different than how data is represented in Relational Database Management Systems (RDBMS) solutions whose main components are tables, rows, columns, and schemas. It is also different than document-based solutions whose main components are keys, values, and document contents. There are effective ways of representing relationships in both RDBMS and Document databases but they are different and those differences affect more than the data realization.
Those differences also affect the way data is queried in graph databases. Querying a database is how we operate on, manipulate and ask questions of the data and its relationships. This typically is bundled into a querying language such as SQL for products like Oracle and MySql and for graph databases it’s no different – though there is less standardization across products where we have languages such as Gremlin, Cypher, and GSQL.
The difference in querying lies in how those querying languages interact with the data. For SQL we query declaratively asking for sets of data that match our request. This is powered by sets and sets math. Performance of the declarative requests is typically enhanced through indexes or short cut value lookups. In document store databases we are typically looking at key and values also with indexes in place to speed up searches or criteria matching.
However, when we look at how querying works in graph databases we must retu\r\n \to math class and remember the idea of a “path”. Let’s bring back our drawing of you and your friends to help us visualize a path.
We will start at “you” and travel the line from you to Todd, that line from you to Todd is a path, we’ve called it an edge before and it still is – but for the moment let’s think of it as a path.
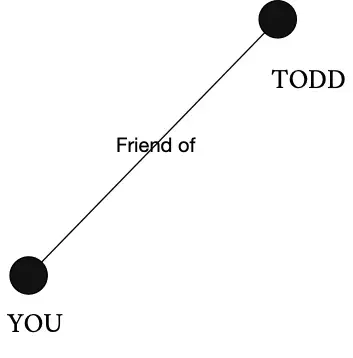
Graph databases gather information by traveling these paths (or edges) in a process called traversal. I like to imagine a little creature traveling along those lines collecting a log of all of the places it went to based on the instructions you gave it in your query.
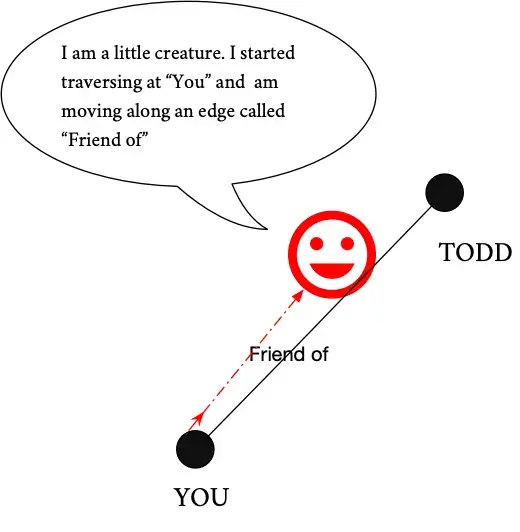
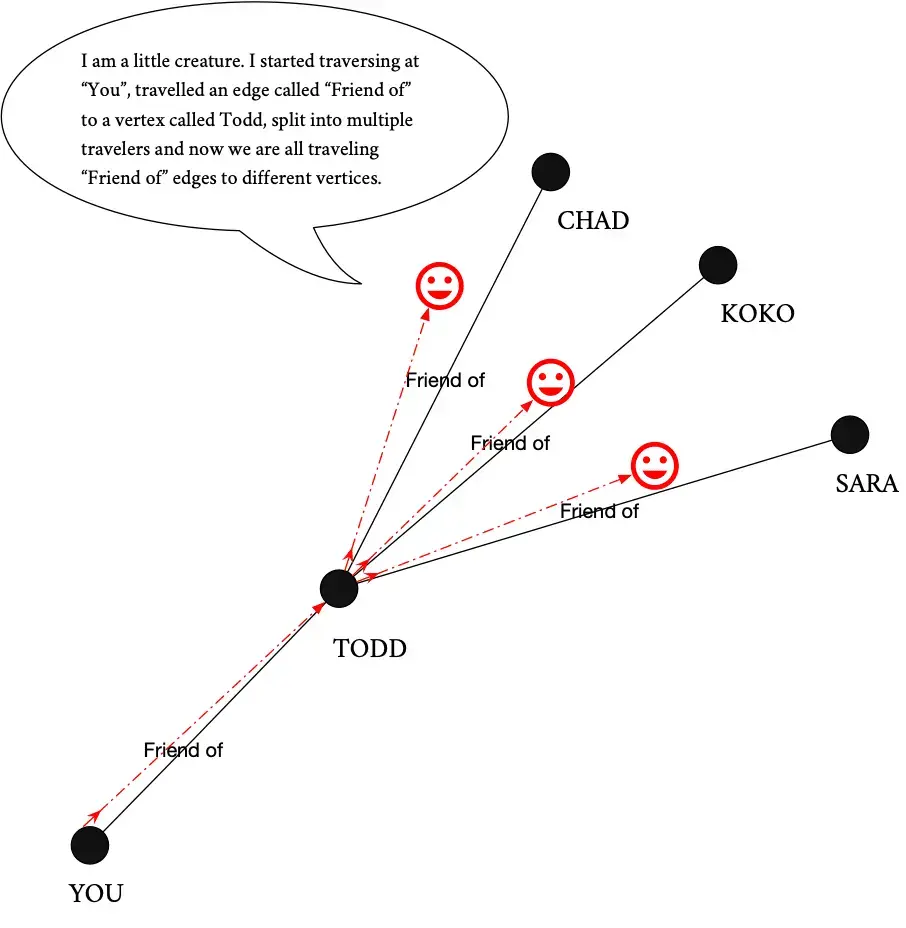
This creature has some magic though – it can split itself into multiple parts when it comes to multiple paths if you want it to – or it can go down one path at a time. Pretty neat skill, however, it comes at the cost that the more times it needs to split up the slower it goes. This querying process has a huge impact on the kinds of questions that graph databases are good at answering.
Some questions are perfect fits for this process of querying ensuring that they run very quickly. These tend to be questions that originate from a known place, a specific vertex or edge. This can also be a series of vertices or edges that have been filtered in some way by something our little traversal creature can understand without having to look to spend too much time looking. These would be things like a particular kind of vertex or edge, some characteristic of the path itself perhaps such as vertices that are at least two edges apart from a particular vertex.
Where graph databases don’t do very well, in our experience, is where the entirety of the graph is concerned or where great multitudes of vertices and or edges must be considered outside of a traversal process. This would be like asking our little traversal creature to split up in to 1000s of versions of itself and since we know that every time we split into more versions things get slower we’d already be starting at a pretty bad disadvantage – that kind of data question is best left to a set based querying system like SQL.
Sometimes there are really complex questions that need to be answered that involve many many vertices and their edge relationships other times we simply have relationship based questions based on a known starting place – such as a specific customer or specific issue – as such graph databases tend to have two overarching use cases one is Online Transactional Processing or OLTP and the other is Online Analytical Processing or OLAP. OLAP applications of graph databases tend to be more useful for those very complex and non-time intensive questions for which a correct answer is very important but getting there in online customer time is not the primary consideration. OLTP applications of graph databases are going to stress transactional efforts like reading and writing but not be tuned for extremely complex or large considerations.
So drop everything and put all your data into a graph database? Hold on there! Not quite. Just like any technology graph databases have their place. As you can imagine based on how we’ve described queries working there are going to be some very exciting uses and some less stellar ones. So where might you consider using a graph database?
Places where you want to store, manipulate, or interpret pieces of data that have known relationships of a highly connected or hierarchical nature. This could be information like magazine or newspaper issues in their volumes over the years with their interconnected authors, topics, interviews, subscriptions and letters to the editor. Graph databases could be use to relate articles to each other, to better understand how stories develop, to connect articles or pieces in a series, to track trends in the publication or reader engagement
Another example is a professional network where interconnected knowledge domains, companies, job seekers, job opportunities and skills intertwine. The graph database could be the glue that connects you and a friend of a friend of a friend to your perfect candidate.
The above examples relied on know or understood relationships – such as a yearly publication being divided into volumes and issues and articles and features. But many graph databases are also ideal for evolving ecosystems of relationships between vertices or entities. They are schemaless. Schemas describe the shapes and rules we know about data, what kinds of data do we have, how are they connected, what rules apply to them. A schemaless database is quite a distinct feature from RDBMS where traditionally schemas help determine data validity and are required for the true power of data integrity in those systems. Only some graph databases are schemaless but those that allow you to add new vertex types and edge types at will.
So it turns out that graph databases can also store, manipulate or interpret data that has evolving or many unknown potential relationships. Some examples of this use case include recording and interpreting customer interactions — perhaps you began as an internet only company but then moved into brick and mortar — the kinds of interactions that can take place can change drastically. Another example is that of a social network that offers third-party games on its platform. These games can introduce brand new concepts for relating players and how they interact with each other that go beyond “like” or “share” and be able to extend your data model to nearly limitless possibilities is a real boon. Finally, AI, machine learning and knowledge graphs can all utilize schemaless graph databases allowing room for new understandings and connections to be formed over the life of the data.
I’m looking forward to writing follow-ups that more closely detail our experience with Graph databases and get you started looking at or even implementing Neptune for your own business. Either way, I hope that next time someone buzzword bombs you with Graph databases you will be armed with a firm understanding of what it is, some understanding of the basic mechanics of it and some of the better places to utilize it.
Making the web a better place to teach, learn, and advocate starts here...
When you subscribe to our newsletter!